

If we had to choose one word to describe the rapid evolution of AI today, it would probably be something along the lines of explosive. As predicted by the Market Research Future report, the large language model (LLM) market in North America alone is expected to reach $105.5 billion by 2030. The exponential growth of AI tools combined with access to massive troves of text data has opened gates for better and more advanced content generation than we had ever hoped. Yet, such rapid expansion also makes it harder than ever to navigate and select the right tools among the diverse LLM models available.
The goal of this post is to keep you, the AI enthusiast and professional, up-to-date with current trends and essential innovations in the field. Below, we highlighted the top 9 LLMs that we think are currently making waves in the industry, each with distinct capabilities and specialized strengths, excelling in areas such as natural language processing, code synthesis, few-shot learning, or scalability. While we believe there is no one-size-fits-all LLM for every use case, we hope that this list can help you identify the most current and well-suited LLM model that meets your business’s unique requirements.
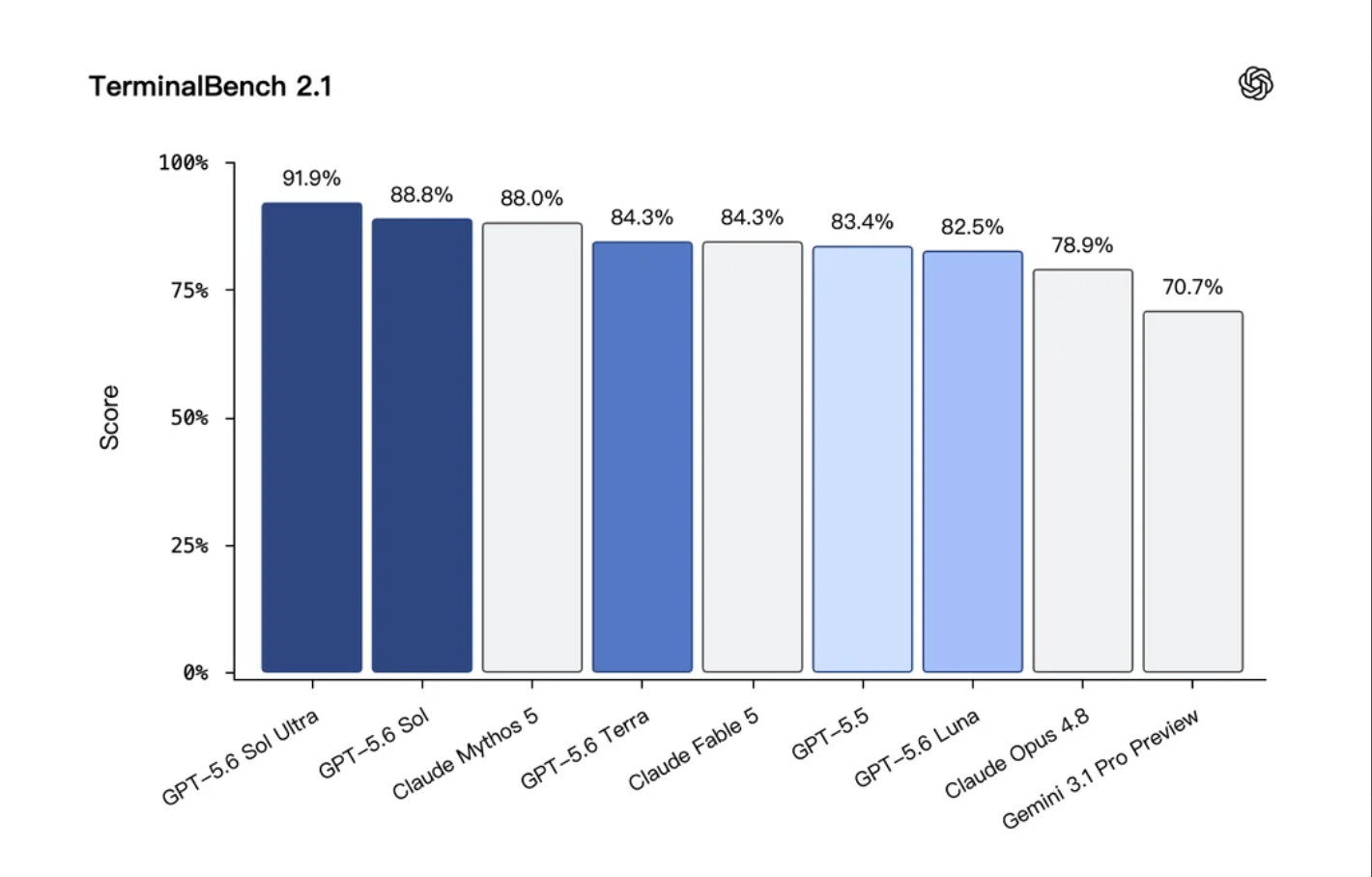
Our list kicks off with OpenAI's Generative Pre-trained Transformer (GPT) models, which have consistently exceeded their previous capabilities with each new release. The company has announced its latest flagship model, GPT-5.5, alongside the GPT-5.6 Sol/Terra/Luna series in limited preview. The new standard features a significantly expanded context window of 400K tokens (up from 128K in GPT-4) and achieves a perfect 100% score on the AIME 2025 math benchmark. Crucially for enterprise reliability, the hallucination rate has been reduced to 6.2%—an approximately 40% reduction from earlier generations.
OpenAI has also made a move into the open-source community with its new "open-weight" models, GPT-oss-120b and GPT-oss-20b. These are released under the Apache 2.0 license, providing strong real-world performance at a lower cost. Optimized for efficient deployment, they can even run on consumer hardware and are particularly effective for agentic workflows powered by Kaji, tool use, and few-shot function calling.
With the release of GPT-5.5, older models like GPT-4o, GPT-4, and GPT-3.5 are being deprecated (with GPT-4.5 retired on June 26, 2026). While GPT-4o was a notable step toward more natural human-computer interaction with its multimodal capabilities, it is now largely superseded. Similarly, the foundational GPT-4 and GPT-3.5 models are considered less capable than the newer GPT-5.5, which is less prone to reasoning errors and hallucinations. Users who built workflows around older models like o3 and o1 may experience frustration as OpenAI consolidates its offerings.
Despite its advanced conversational and reasoning capabilities, GPT remains a proprietary model. OpenAI keeps the training data and parameters confidential, and full access often requires a commercial license or subscription. We recommend this model for businesses seeking an LLM that excels in multi-step reasoning, conversational dialogue, and real-time interactions, particularly those with a flexible budget.
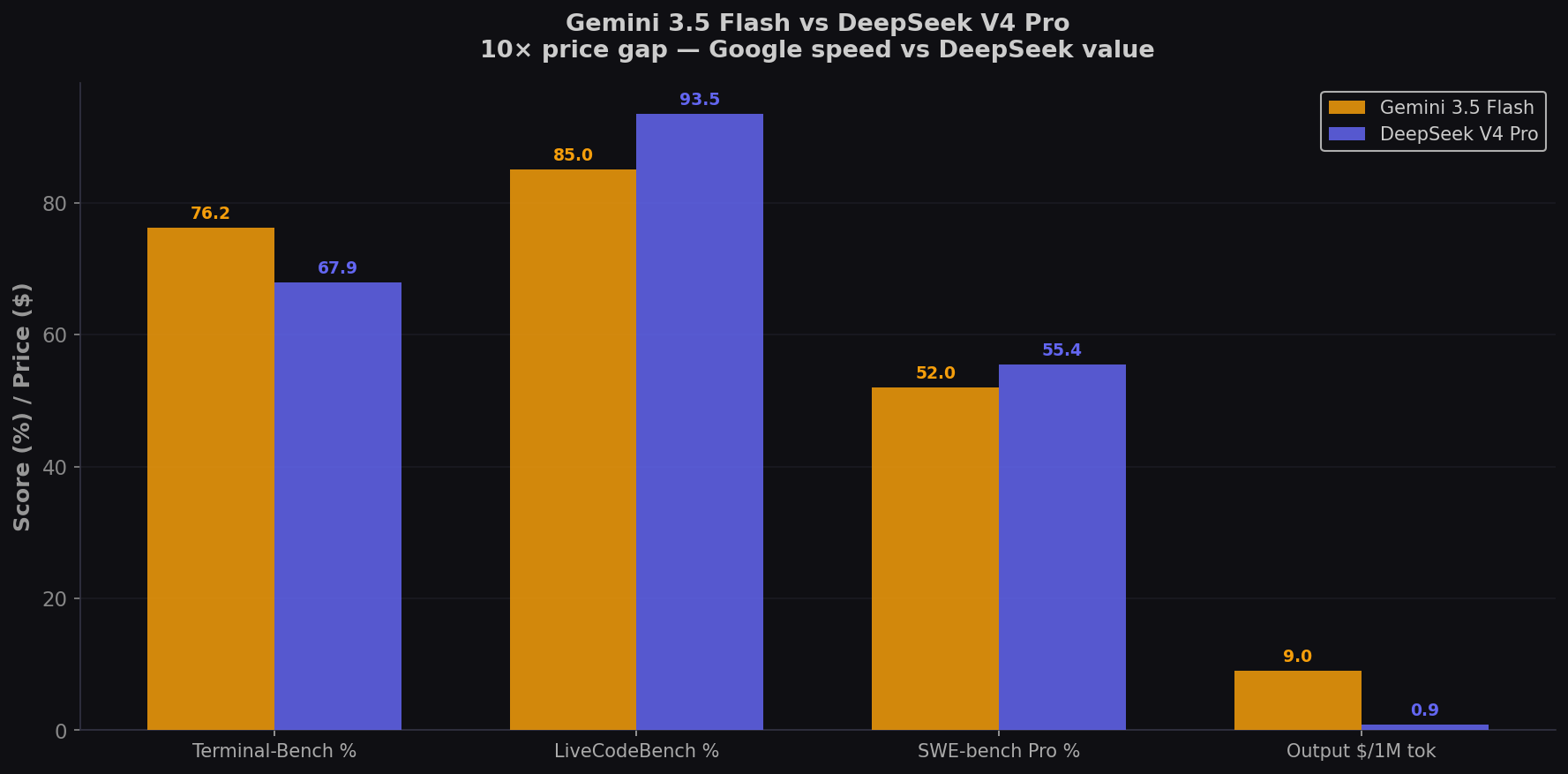
DeepSeek, a Chinese AI company, has continued to push the boundaries of AI innovation with a focus on both specialized and versatile models. As of mid-2026, DeepSeek has been actively releasing and updating its models, from the DeepSeek-V3.2-Exp and the DeepSeek-R1 series to the latest DeepSeek-V4 family (previewed April 2026). DeepSeek-V4 Pro features 1.6 trillion total parameters (49B active) while V4 Flash offers 284B parameters (13B active), both supporting a 1M token context window. A full public launch is expected mid-July 2026.
This model introduces 'Fine-Grained Sparse Attention,' a first-of-its-kind architecture that improves computational efficiency by 50%. For enterprises focused on ROI, DeepSeek offers an aggressive pricing structure, with input costs as low as $0.07/million tokens (with cache hits). It is also the first model to integrate 'thinking' directly into tool-use capabilities, bridging the gap between reasoning and action.
For advanced reasoning, the DeepSeek-R1 series was introduced, which includes models like R1-Zero and R1. The R1 series is specifically designed for high-level problem-solving in areas such as financial analysis, complex mathematics, and automated theorem proving.
DeepSeek also released the DeepSeek-Prover-V2, an open-source model tailored for formal theorem proving in Lean 4. To make these powerful capabilities more accessible, DeepSeek has also developed the DeepSeek-R1-Distill series, which are smaller, more efficient models that have been "distilled" from the larger R1 model. These distilled models, based on architectures like Qwen and Llama, are perfect for production environments where computational efficiency is a priority.
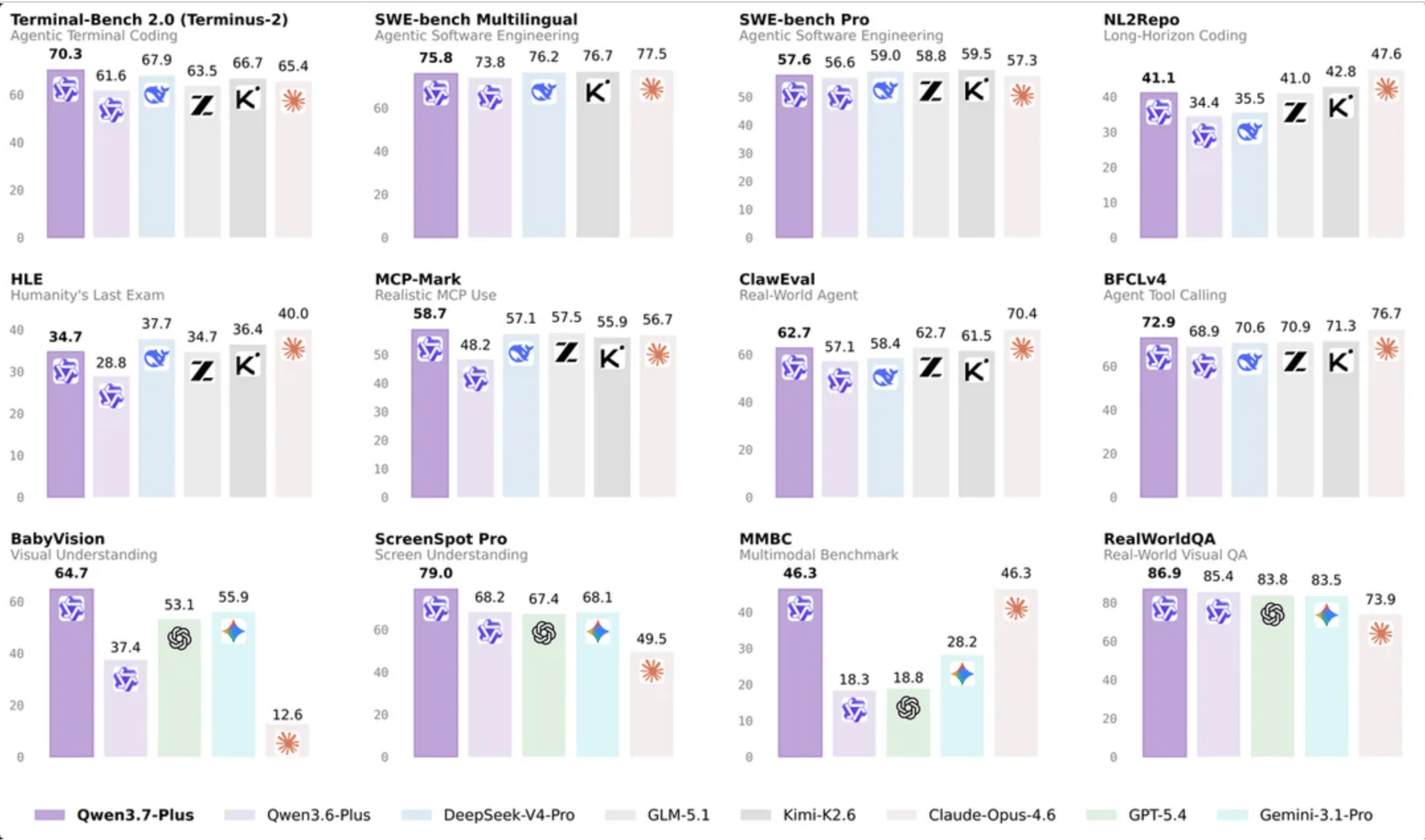
Alibaba has been actively advancing its language model lineup, with the latest major releases centered around the Qwen3 series. These hybrid Mixture-of-Experts (MoE) models reportedly meet or beat GPT-5.5 and DeepSeek-V4 on most public benchmarks while using far less compute.
Alibaba’s Qwen 3.7-Max/Plus and the massive Qwen3-235B-A22B-Thinking have redefined the open-weights landscape. With a parameter scale exceeding 1 trillion via MoE architecture, Qwen now supports 119 languages and achieves 92.3% accuracy on AIME25. It is particularly strong in real-world coding, scoring 74.1% on LiveCodeBench v6. Alibaba reports that these models now outperform GPT-5.5 and Llama-4 Maverick on key benchmarks, making them a heavy hitter for global, multilingual deployments.
The models in the Qwen family, spanning from 4 billion to 235 billion parameters, are open-sourced under the Apache 2.0 license and available through multiple platforms including Alibaba Cloud API, Hugging Face, and ModelScope. The Qwen3 series also includes traditional dense models like the Qwen3-32B and Qwen3-4B, which are highly flexible and can be deployed in various settings. For specialized tasks, there are models like Qwen3-Coder for software engineering, Qwen-VL for vision-language applications, and Qwen-Audio for audio processing.
For businesses and developers, the Qwen family has gained significant traction, with adoption by over 90,000 enterprises across consumer electronics, gaming, and other sectors.
Grok is the generative AI chatbot from xAI, integrated with the social media platform X to offer real-time information and a witty conversational experience. The Grok family of models is designed as a tiered lineup, with each model optimized for a different purpose.
Released as the flagship model, Grok 4.3 (with Grok 4.5 in private beta since June 28, 2026) has taken the lead in pure reasoning. It currently holds the #1 position on the LMArena Elo ranking and EQ-Bench. Most notably for business use, the hallucination rate has dropped to just over 4%—a significant reduction. In blind A/B tests, users preferred the newer model nearly 65% of the time over the previous production model.
For developers, Grok Code Fast 1 (and the Grok Build 0.1 coding agent) is a specialized, cost-effective model built for "agentic coding," excelling at automating software development workflows, debugging, and generating code.
These recent models build on the foundation laid by their predecessors. Grok 4.1 and Grok 3 introduced advanced reasoning capabilities with a "Think" mode for step-by-step problem-solving and a "DeepSearch" function for in-depth, real-time research. Grok 2 was the first to introduce multimodality, including image understanding and text-to-image generation.
Given this diverse lineup, Grok is recommended for a range of applications. Grok 4 is ideal for heavy research, data analysis, and expert-level problem-solving. Grok Code Fast 1 is the go-to for software development where speed and cost are a priority. For a balance of speed and quality, the Grok 3 models are well-suited for advanced problem-solving, education, and real-time analysis of current events.
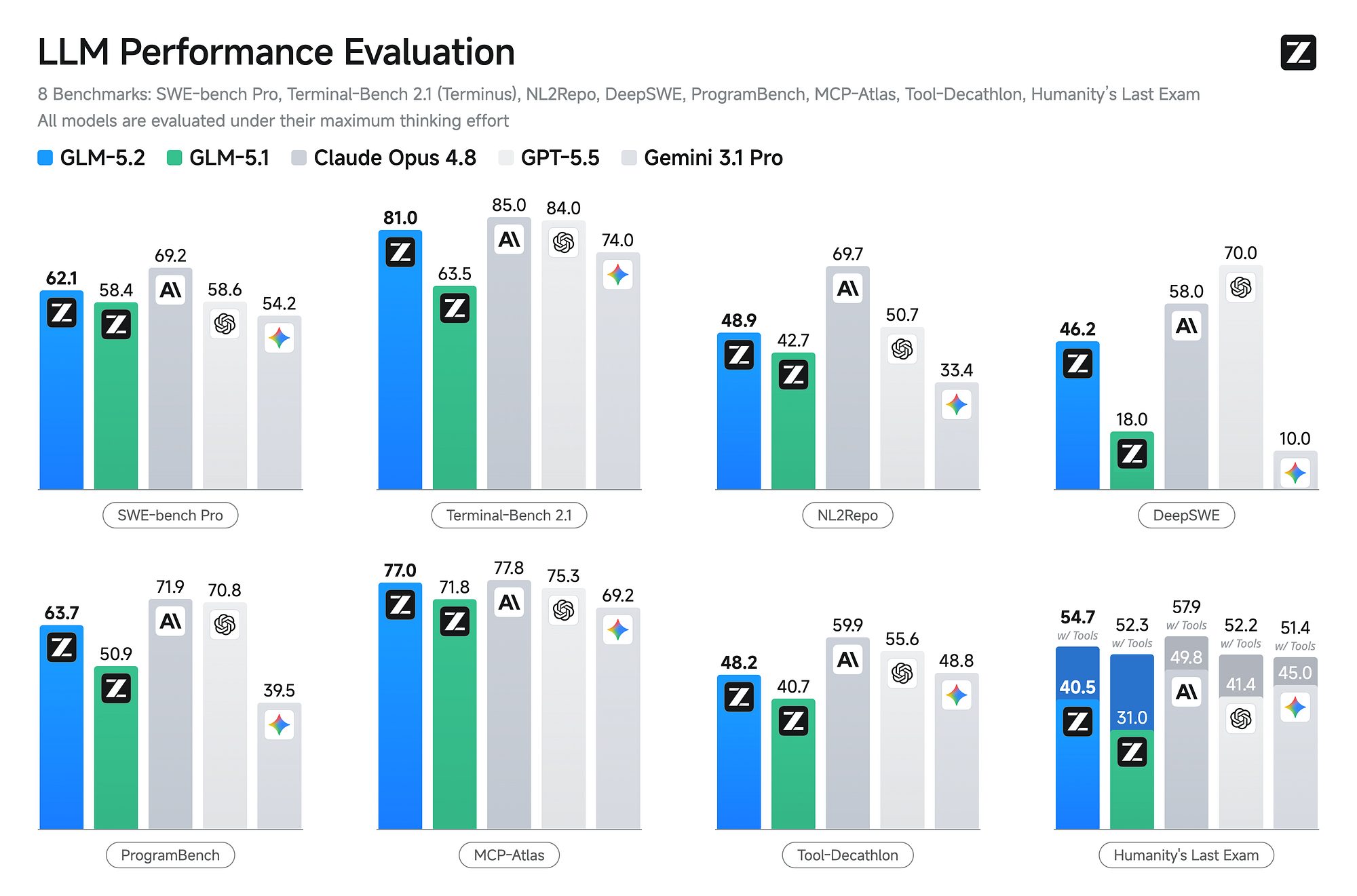
Zhipu AI (Z.ai), a Beijing-based AI company spun out of Tsinghua University, has rapidly become one of the most significant players in the open-weight LLM space. The company went public on the Hong Kong Stock Exchange in January 2026 and has since seen its market cap exceed 1 trillion RMB (~$140B USD). Its latest flagship model, GLM-5.2, is a 744-billion parameter Mixture-of-Experts model with approximately 40 billion active parameters per token, released in June 2026 under the permissive MIT license.
GLM-5.2 currently ranks as the #1 open-weight model on the Artificial Analysis Intelligence Index v4.1. On SWE-bench Pro, it scored 62.1%, surpassing GPT-5.5's 58.6%—a significant achievement for an open-weight model. The model features a 1 million token context window, enabled by its novel IndexShare architecture that reuses sparse-attention indexers across layers for a 2.9x reduction in per-token compute at extreme context lengths.
A notable aspect of GLM's development is its complete independence from NVIDIA hardware. The entire GLM-5 series was trained on Huawei Ascend chips using the MindSpore framework—a geopolitical milestone proving that frontier AI models can be built without access to US-manufactured GPUs. This makes GLM particularly appealing for enterprises seeking geopolitical resilience in their AI supply chain.
The GLM model family spans from the lightweight GLM-4.6V-Flash (9B) for edge deployment to the full GLM-5.2 flagship. Specialized variants include GLM-5V-Turbo for multimodal vision tasks and the AutoGLM agent framework for complex multi-step task planning. For developers, the ZCode coding agent is powered by GLM. The models are available on Hugging Face, and API pricing starts at $0.94/million input tokens—significantly cheaper than proprietary alternatives while matching or exceeding their performance. With its MIT license, strong bilingual Chinese-English capabilities, and competitive benchmarks, GLM is an excellent choice for businesses seeking a powerful, self-hostable alternative to closed-source models, particularly those operating in or serving the Chinese market.
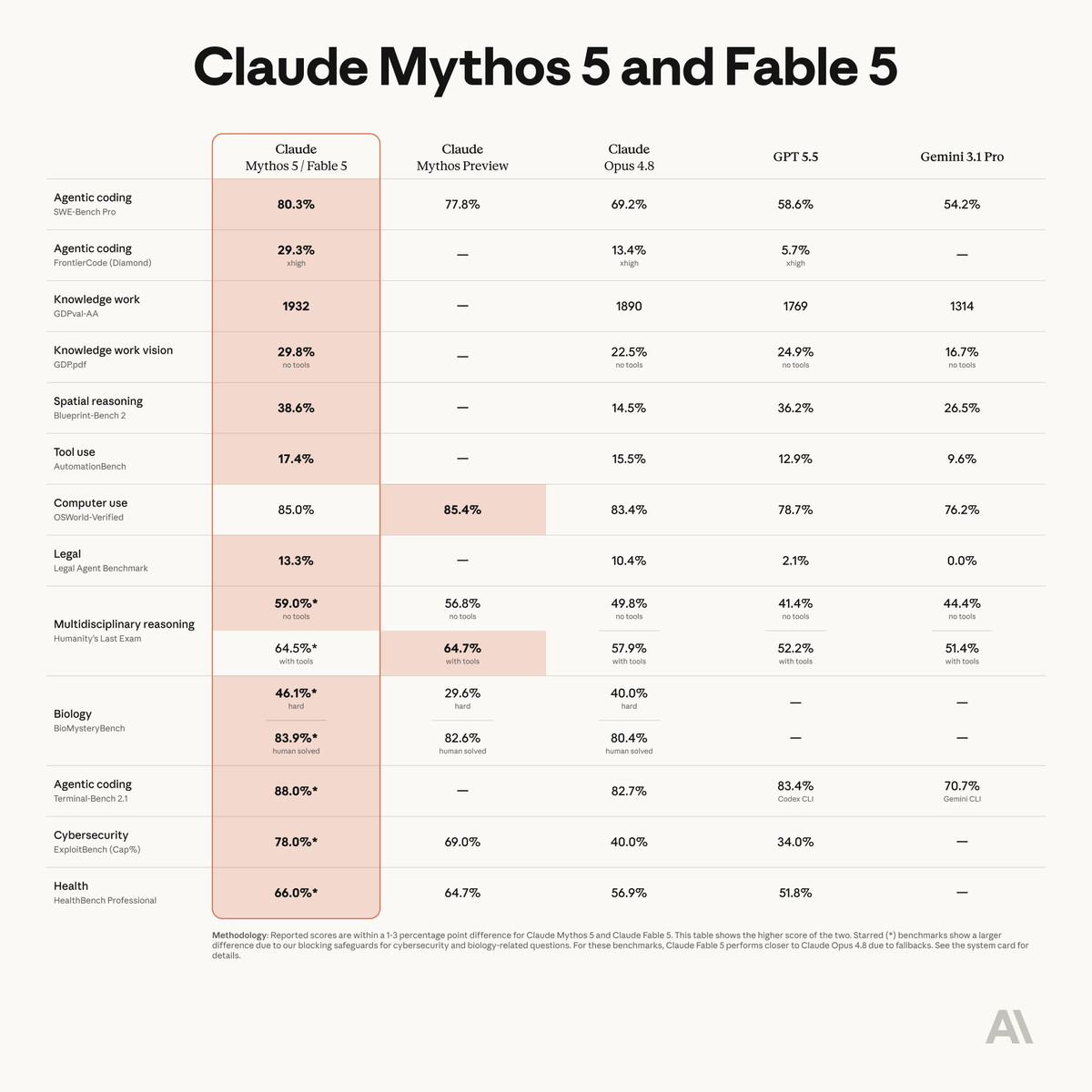
Anthropic’s latest flagship models, the Claude 5 family (led by Claude Fable 5 as the public flagship), build on the foundation of the Claude 4 and 3 series by integrating multiple reasoning approaches. A standout feature is the “extended thinking mode,” which leverages a technique of deliberate reasoning or self-reflection loops. This allows the model to iteratively refine its thought process, evaluate various reasoning paths, and optimize for accuracy before finalizing an output, making it suitable for complex, multi-step problem-solving.
Claude models are designed as a versatile family, with each model balancing intelligence, speed, and cost. While older Claude 4 models like Sonnet 4 and Opus 4 were deprecated on June 15, 2026, the lineup has consolidated around Claude Fable 5 (best-in-class reasoning and multi-step tasks) and Claude Opus 4.8 (available for long-running workflows). Claude Fable 5 is considered the best for real-world agents and coding, and can autonomously sustain complex, multi-step tasks for over 30 hours, while also being an all-around performer optimized for enterprise workloads like data processing.
The lineup now includes Claude Fable 5, alongside the restricted-access Claude Mythos 5 for specialized enterprise reasoning. The series is currently unmatched in computer use, scoring 61.4% on OSWorld (previous bests were ~45%).
On the coding front, the Claude 5 series achieved 77.2% on SWE-bench Verified, maintaining context over 6+ hour debugging sessions with an 89% success rate. For enterprises, Fable 5 offers higher performance while using 48% fewer tokens than previous high-effort models.
While the older Claude models featured a 200K-token context window, the newer Claude 5 models offer an impressive 200K token window (with a beta 1 million token context window on Fable 5), allowing them to process lengthy documents. The models are multimodal, capable of processing both text and images, and have introduced new features like "computer use," which allows them to navigate a computer's screen with enhanced proficiency. Overall, the Claude family is a strong competitor to models like Google's Gemini and OpenAI's GPT-5, consistently performing well on benchmarks for solving mathematical problems.
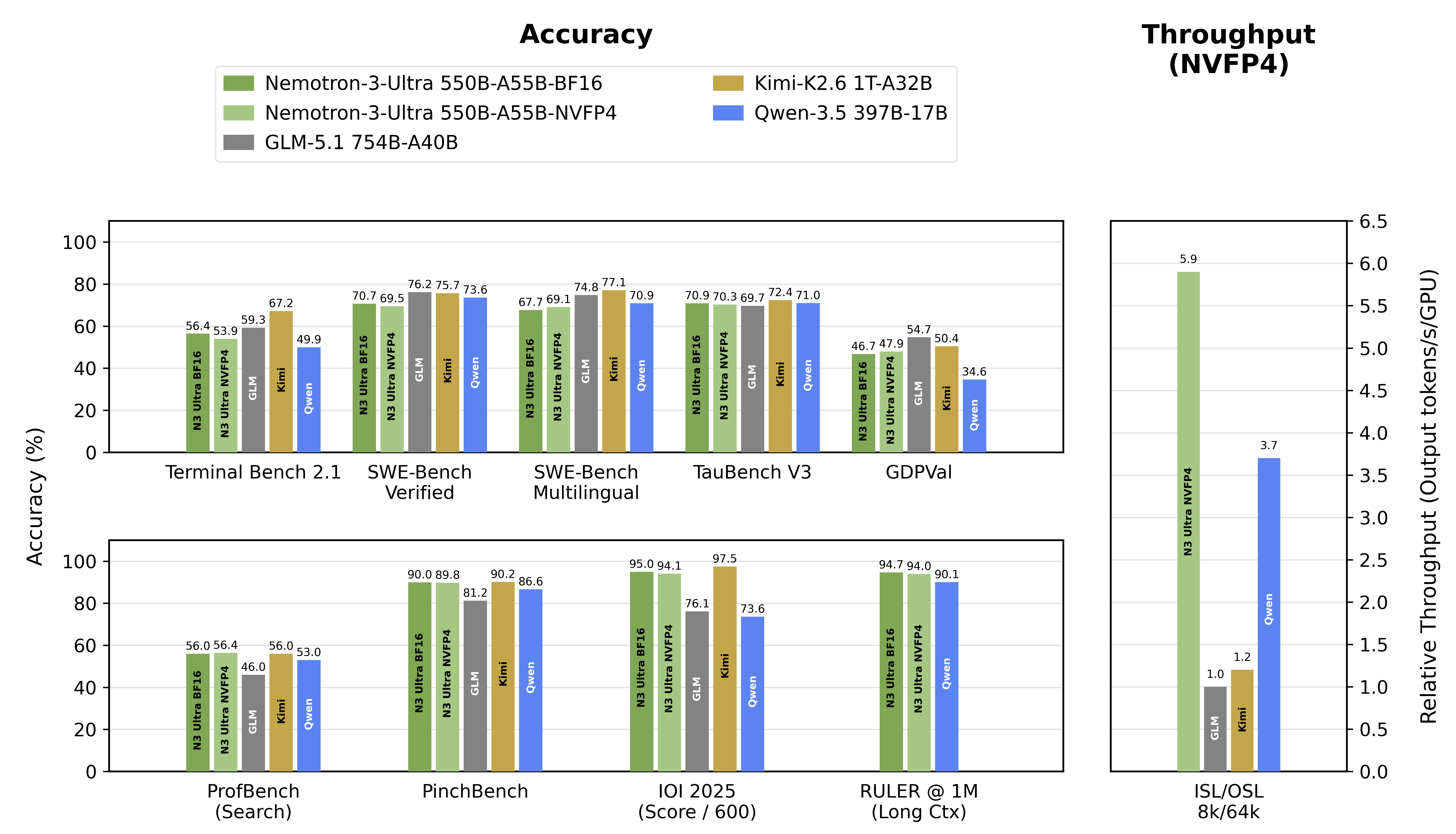
NVIDIA's Nemotron family represents a unique proposition in the LLM landscape: a frontier-class model built by the company that also designs the GPUs it runs on. The latest flagship, Nemotron 3 Ultra (announced at Computex, June 2026), features 550 billion total parameters with 55 billion active per forward pass, a 1 million token context window, and is released under NVIDIA's permissive OpenMDW-1.1 license.
What sets Nemotron apart architecturally is its hybrid Mamba-Transformer MoE design—combining Mamba-2 state-space model layers with traditional Transformer attention layers in a Latent Mixture-of-Experts configuration. This novel approach delivers up to 5x faster inference compared to dense models of equivalent capability. Multi-Token Prediction further boosts throughput by generating multiple tokens per forward pass. On the AIME 2025 benchmark, the mid-range Nemotron 3 Super (120B) scored 90.21%, while the Ultra model achieves a score of 90.0 on PinchBench and 56.0 on ProfBench, competing with GPT-5.5 and Claude Fable 5 on agentic reasoning tasks.
The Nemotron 3 family is organized into three tiers: Nano (30B total, 3B active) for edge and real-time tasks including a multimodal Nano Omni variant that handles video, audio, image, and text; Super (120B total, 12B active) for complex enterprise agentic workflows; and Ultra (550B total, 55B active) as the frontier reasoning model. NVIDIA also maintains the Llama Nemotron family—models derived from Meta's Llama architecture but heavily post-trained with Neural Architecture Search, knowledge distillation, and multi-phase RLHF, featuring a unique dynamic reasoning toggle that switches between fast chat and deep chain-of-thought modes at inference time.
NVIDIA's full vertical integration is Nemotron's ultimate differentiator. The models are optimized for deployment via NVIDIA NIM (inference microservices with TensorRT-LLM), and are available for free prototyping on the NVIDIA API Catalog. For production, enterprises can self-host using the open weights at no model cost, or deploy via cloud partners (AWS, Azure, GCP) with NVIDIA AI Enterprise support at ~$4,500/GPU/year. The models also run on community frameworks like vLLM, SGLang, and Ollama. For businesses already invested in the NVIDIA ecosystem, Nemotron offers an unmatched combination of hardware-software co-optimization, open weights, and enterprise-grade support.
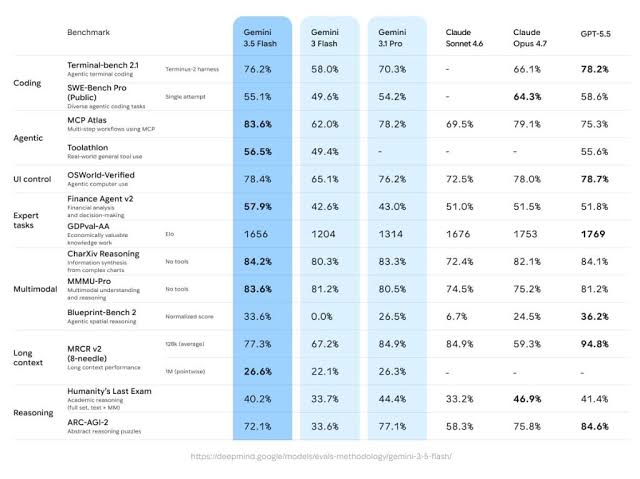
Google’s Gemini 3.5 Flash (production since May 19, 2026) and the upcoming Gemini 3.5 Pro (coming July 2026) have shown massive improvements. Gemini 3.5 Pro features a 1M token context window and achieved a staggering 100% on AIME 2025 (with code execution).
The 'Deep Think' capabilities in Gemini 3.5 have improved reasoning scores by a factor of 2.5x compared to previous generations (ARC-AGI-2 score of 45.1%). For developers, Gemini 3.5 Flash is a standout, achieving 78% on SWE-bench Verified, outperforming even the Pro version in specific coding tasks.
For developers and businesses, Google offers several specialized versions of Gemini 3.5. The Gemini 3.5 Flash and Flash-Lite models are optimized for high-speed, cost-efficient, and latency-sensitive tasks like classification and translation. Google has also introduced specialized models, including Gemini 3.5 Flash Image, internally called "Nano Banana" for advanced image editing, and the state-of-the-art video generation model, Veo 3. Veo 3 can create high-fidelity, short videos from text or images and is integrated into the Gemini app.
While Gemini is a proprietary, closed-source model, Google also provides the Gemma family of open-source models, built from the same research. Gemma 3 supports a context window of up to 128,000 tokens and is available in various parameter sizes, making it an ideal, flexible alternative for developers, academics, and startups who need to fine-tune and deploy models locally with greater control.
Given that Gemini is a proprietary model, companies handling sensitive or confidential data must ensure vendor compliance with data privacy and security standards such as GDPR and HIPAA. This due diligence is crucial to mitigate security concerns related to sending data to external servers.
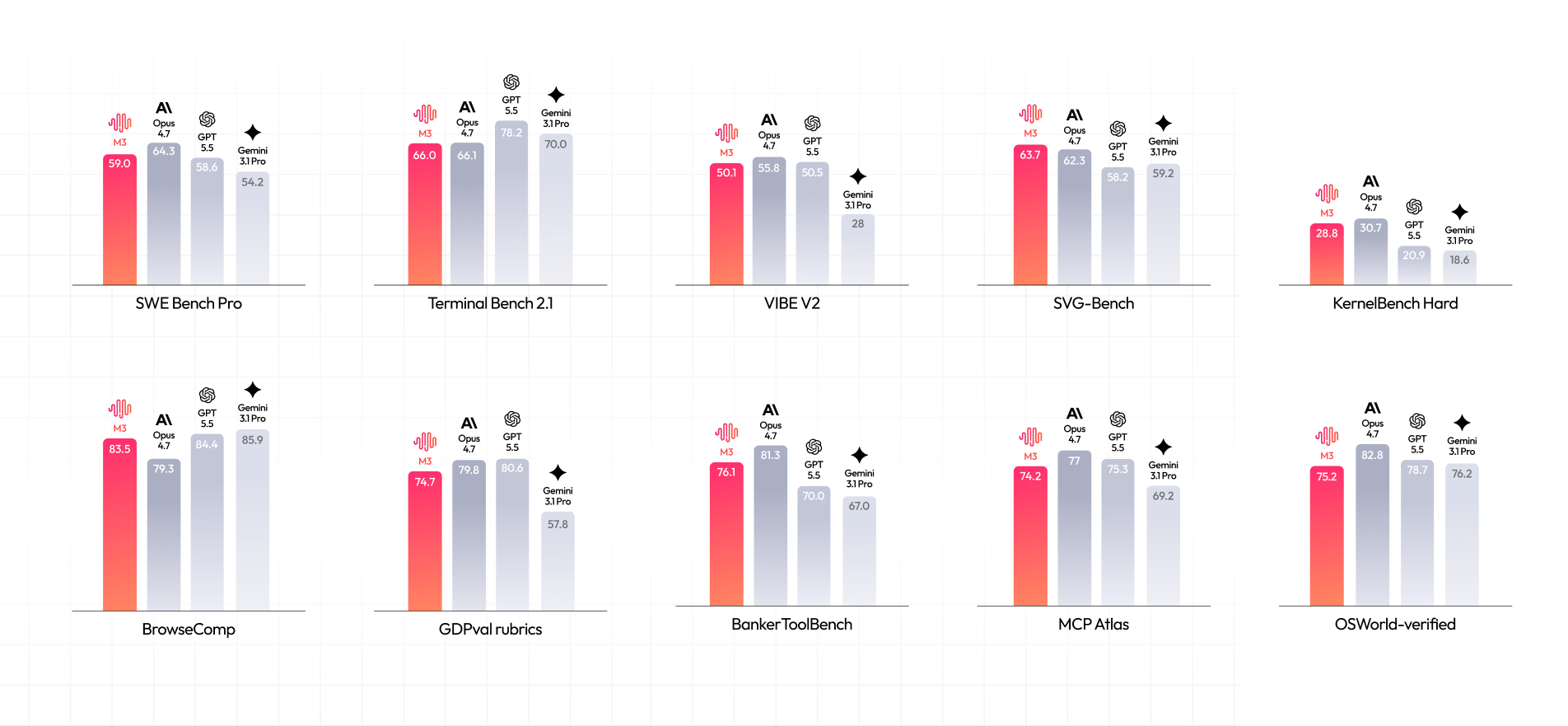
MiniMax, a Shanghai-based AI company that IPO'd on the Hong Kong Stock Exchange in January 2026 (raising $619 million at a ~$13.7B valuation), has emerged as one of China's most formidable AI companies—known as one of the country's "AI Tigers." Backed by Alibaba, Tencent, and Hillhouse Capital, MiniMax now serves over 1 million enterprise and developer clients worldwide. Its latest flagship, MiniMax M3 (released June 2026), is a 428-billion parameter MoE model with just 23 billion active parameters per token, offering frontier-level performance at a fraction of the compute cost.
MiniMax's core architectural innovation is its proprietary Lightning Attention, which eliminates the quadratic O(n²) scaling of standard transformers and reduces it to linear O(n) complexity. This breakthrough, evolved into MiniMax Sparse Attention (MSA) in M3, enables the model to handle a 1 million token context window efficiently. The earlier MiniMax-Text-01 model still holds the record for the longest inference context at 4 million tokens. On SWE-bench Pro, M3 scored 59.0%—slightly ahead of GPT-5.5's 58.6%—while also achieving 83.5 on BrowseComp and 66.0% on Terminal-Bench 2.1.
What makes MiniMax unique among LLM makers is its full multimodal product stack. Beyond text models, the company offers Hailuo AI for physics-accurate 1080p video generation (with Director Mode for cinematic control), MiniMax Speech for real-time multilingual text-to-speech, and MiniMax Music for text-to-music generation. The Talkie companion app adds consumer reach. This breadth means enterprises can source text, vision, video, audio, and speech capabilities from a single vendor.
For enterprises focused on cost efficiency, MiniMax's API pricing is exceptionally aggressive at just $0.30 per million input tokens and $1.20 per million output tokens—making it one of the most affordable frontier-class models available. The models are open-weight and available on Hugging Face for self-hosted deployment. MiniMax also offers global infrastructure through AWS and GCP partnerships, and has established enterprise partnerships in telecom (GSMA member operators for 5G-Advanced integration) and customer experience (Agora, uDesk). For businesses seeking a versatile, cost-effective alternative to Western proprietary models with strong multimodal capabilities, MiniMax is a compelling choice.




















